变分推断实际上是一个老议题,自从变分自编码器 (VAE) 横空出世以来[1],中英文资料都相当多(尽管事实上变分推断的出现远早于 VAE 的诞生),但是基于目前的资料看来,基本只有 PRML 或者 [2] MLAPP [3] 这类老牌英文教材才有严谨细致的表述,并且动机明显,而中文资料却缺乏详细的表述和推导。时至今日入门变分推断在中文互联网也不是一个容易的事情。为此我想通过更加简单的叙述来慢慢实现变分推断的入门。
为接下来的分析方便,本文假定读者具有良好的微积分和线性代数基础,但无需泛函分析基础。
变分法:“变分”的来源
无论是变分推断还是变分自编码器,核心都来源于一个重要的数学方法为变分法:泛函的极值求解方法。变分法 (Calculus of Variations) 相比于求解函数的极值,会针对更加广泛的泛函。对于变分推断感兴趣的读者如果未曾学过泛函分析,可以简单理解泛函的定义。
泛函和算子
定义 1:泛函是一个由线性空间 映射到 标量域(例如 或者 )的映射。
可能一些读者通过搜索等方式了解泛函,知道在其他的地方被描述为“函数的函数”,这种说法不能称之为错误,而是可以作为一种直观理解的方式。我们这里需要简单区分一下几个名词:
- 函数:在多数时候和“映射”是等同的描述;
- 泛函:从线性空间到其标量域的映射;
- 算子:从线性空间到线性空间的映射。
一些很重要的例子:勒贝格可积函数全体构成的空间记为 空间,它是一个赋范线性空间,那么全空间上的积分实际上可以视为一个泛函:
这里 为定义域,即 就是一个泛函。同时还有一些很简单的例子,例如在一个知乎文章上的例子:文中定义了一个 为泛函,而函数 来自多项式空间 (这也是一个线性空间),那么按照原文的定义方式其实就是 ,这个体系并不蠢,关键在于我们研究的问题是怎么样的。熟悉概率论的读者可能知道一个概念是信息熵,对于离散随机变量 ,其信息熵为
这实际上还是一个泛函,因为随机变量如果根据 Kolmogrov 公理体系就是一个函数。如果细心留意,我们其实早就和泛函打交道了。
变分法:求泛函的极值
在学习微积分的时候,可以知道无论是导数,还是 Lagrange 乘子法,主要针对的对象都是常见的函数,但是对于泛函,以往的计算方式就乏力了。变分法在此时就有重要的作用。变分法的起源是著名的最速降线问题 [4]:寻找一个最优的弧面曲线 ,满足如下的质点运动时间最小:
这实际上就是一个最小化泛函的问题,时至今日,变分法已有较大的发展,一个重要分枝就是本文将要讨论的变分推断。
变分推断及其主要目的
贝叶斯推断的一个问题
贝叶斯统计是概率统计当中的一大主题,而贝叶斯推断是统计推断这个传统主题在贝叶斯统计下的重要论题。无论是贝叶斯机器学习还是贝叶斯传统统计问题,都基于贝叶斯公式的思想解决问题。其中一个最为常见的场景是这样的:任务当中一般引入的统计模型会有隐变量 (latent variable) ,它在机器学习场景下往往是参数,例如线性回归的系数,也可以是任何我们不能直接观测到的变量,那么此时我们会给定模型假设 ,我们现在主要的想法是根据观测到的信息来推断隐变量,即得知 ;对于隐变量,我们尝尝会有先验分布 的判断(可以是对参数假设了服从高斯分布或其他已知分布等)。根据贝叶斯公式可以知道:
但是问题出在这个公式的计算上,分母的计算是积分运算,它是相当困难的,通常可能需要数值积分计算,但是如果参数量较大,上述的积分运算就会相对困难,并且这样计算出来的分布很多时候也是不便于我们接下来的分析的。为此,以往的统计学家们试图通过其他的方式来解决。一种就是 MCMC 这类随机方法,它们往往很慢,尽管准确率实际上比较高,但也不便于应用。另外一个就是今天的主角:变分推断。
变分推断
变分推断是一个确定性近似方法 [5],因为它不会引入任何的随机采样,而是依靠优化算法来实现目的。我们假定一个分布 ,这里 是一个固定的分布族,可以是指数族,也可以对分布的结构作出要求而不局限于某类分布。然后让这个分布和真实分布的距离尽可能小。衡量分布的距离通常使用信息论当中的(反向) KL 散度
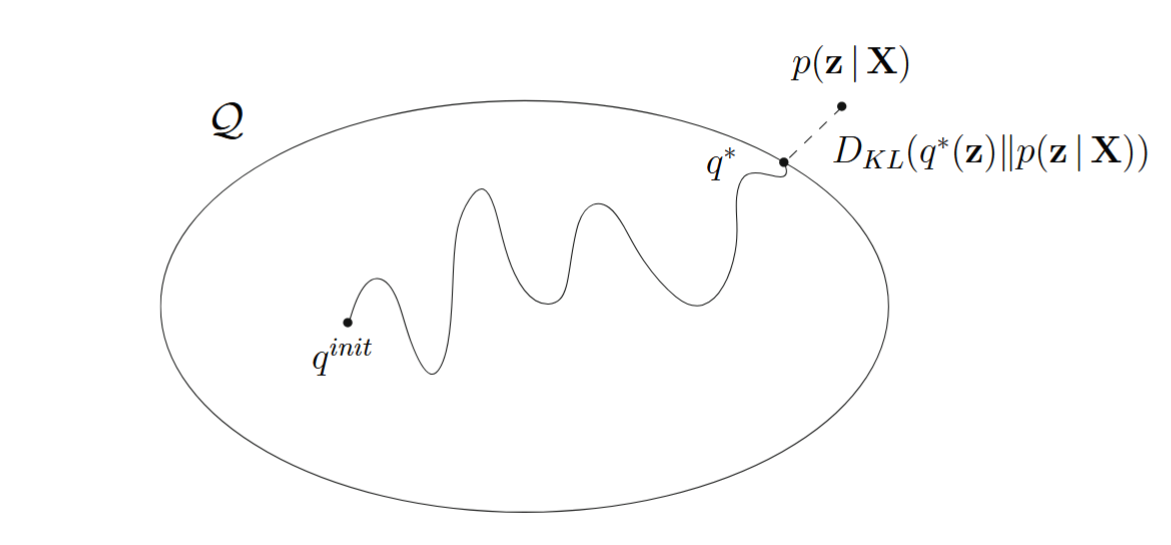
当它达到最小化,说明我们就找到一个距离真实分布最优的近似分布 ,一个几何阐述就是本文的头图,我们相当于利用变分法的思想,最小化 KL 散度这个泛函,最小化的方式一般是通过迭代法,因此这种方法也可以视为一种变分优化方法。
这实际上引入了一些新的问题:
- KL 散度当中有真实分布,但它是未知的,这又如何解决?
- 对于新的积分仍然不可避免积分难算的问题;
- 分布族 如何挑选?
这些都是全新的问题,在之后我们将逐渐解决这些新问题,并慢慢理解变分推断的真实面目。
- Diederik P. Kingma,Max Welling. 2022. “Auto-Encoding Variational Bayes.” Arxiv. https://doi.org/10.48550/arXiv.1312.6114.
- Bishop, Christopher M.. 2006. Pattern recognition and machine learning. New York: Springer. ↩︎
- Murphy, Kevin P.. 2022. Probabilistic machine learning: an introduction. Cambridge, Massachusetts: The MIT Press. ↩︎
- 老大中. 2015. 变分法基础. 北京: 国防工业出版社. ↩︎
- Blei, David M., Alp Kucukelbir, and Jon D. McAuliffe.. 2017. “Variational Inference: A Review for Statisticians.” Journal of the American Statistical Association 112, no. 518: 859-877. https://doi.org/10.1080/01621459.2017.1285773.
留言