身为数学系的学生,经过四年的本科学制学习,发现自己其实数学这个老本行其实还是学的不够,究其原因在于虽然一般数学系的《高等代数》课程包含的内容比一般的线性代数课程多出了一些相对高深点的内容,包括 矩阵以及 Jordan 标准形。但是在后续的学习当中,实际上对分析学还有线性代数有更高的要求。哪怕是很多数学系同学都怒喷“可解释性差”的深度学习,也涉及到矩阵微分这种高等代数不涉及的内容。
矩阵微分是数学分析当中多变量微分的推广,在数学分析当中我们学过了多变量微积分,涉及到梯度等概念。在后续的研究当中,包括矩阵优化在内的主题都会包含矩阵微分,这也是为什么我开始进行这样一个系列的学习。
符号说明
- 对于变量,小写粗体为实列向量变量,例如 ;
- 对于变量,大写粗体为实矩阵变量,例如 ;
- 对于函数,小写普通字母是正常的实值函数,小写加粗字母表示输出为列向量的向量函数,大写加粗字母表示输出为实矩阵的矩阵函数(当然,输出是实矩阵的映射其实更应该叫做泛函,但是在这里还是用函数),例如 .
对于矩阵:
考虑向量化的运算 ,定义为每列衔接得到的列向量:
Jacobian 矩阵和梯度矩阵
Jacobian 矩阵
实值函数的 Jacobian 矩阵
在这里我们主要讨论实值函数和矩阵函数的微分,向量函数微分可以视为矩阵函数微分的一个特例。
实值函数其实就是我们熟悉的多变量函数,这种函数的微分在数学分析当中已经有详细说明,如果实值函数的输入是向量,那么此时的 Jacobian 矩阵就是梯度:
如果输入是矩阵,那么此时的 Jacobian 矩阵定义也相对比较简单:
矩阵函数的 Jacobian 矩阵
现在考虑实值矩阵函数 的情形,其定义很清晰明确:
其具体表达式为:
这种定义是相对比较合理的,在不同教材上实际上会出现很多种定义,有的定义是明显不合适的。
不合适的矩阵函数微分定义
一些矩阵函数的 Jacobian 矩阵的定义是很糟糕的,例如一个看似很合理的定义:
它的不合理之处在于对于一些基本的矩阵函数,它的 Jacobian 矩阵都是非常不符合逻辑的,例如 ,如果使用这种错误的定义来计算 Jacobian 矩阵,那么此时的结果就是 ,这是一个秩为 1 的矩阵,我们并不希望看到这一点,我们会更希望与一元函数导数保持一致,从而应该是满秩。
梯度矩阵
梯度矩阵实际上就是 Jacobian 矩阵的转置。在这里我们主要介绍梯度算子 ,也称为列向量偏导算子,因为一般它对一个实值函数作用后得到的是一个列向量:
如果是行向量偏导算子,其实就是转置一下。对于实矩阵函数 ,那么梯度矩阵实际上就是 Jacobian 矩阵的转置。梯度的负方向称为函数 的梯度流 (gradient flow).
一些实例计算
例题 1:计算实值函数 的 Jacobian 矩阵。
这就是最常见的二次型函数 Jacobian 矩阵,由于 ,所以 Jacobian 矩阵是一个行向量,其第 个分量为
因此可写出其 Jacobian 矩阵 .
例题 2:计算实值函数 的 Jacobian 矩阵,其中 .
根据矩阵输入实值函数的 Jacobian 矩阵定义,可以计算 Jacobian 矩阵第 行 列的元素,在此之前
因此 Jacobian 矩阵和梯度矩阵分别为

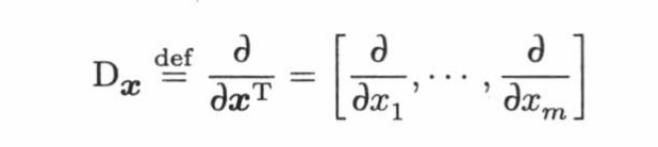
留言