Vibe Reading?记录一个 Obsidian 下的实践

动机
之前读论文一直用的是网页版 AI,用久了之后感觉碰上了挺多痛点的:
- 阅读论文的时候,每次都要说自己是一个“八旬老人”或者“智障本科生”,但是尽管这么说了,它还是无法得知我具体的知识水平;
- 对于理科而言,符号很重要,不熟悉的符号我感觉阅读速度都下降不少,但是在网页端,它只会忠于原论文的符号,而不是我的;
- 还有重要的一点:不同 AI 输出的数学公式想剪藏都各有各的问题,尤其是公式每次都要手调;
- 幻觉,这个来源其实也依赖于我们的个性化,如果我们强烈要求其说的话必须附上原文或者参考文献原文,那么其实幻觉率是可以降低的;
- 网页端 PDF 的解析简直就是沟施,很多粗体的公式无法分辨,造成符号混用,这点在数学论文上很致命。
但是,我同时也是一个 Obsidian 的忠实用户,我的笔记都写在 Obsidian 当中,那么能否直接在 Obsidian 里面进行 Vibe Reading?
一点碎碎念
Vibe reading 在这里我感觉其实和 Vibe coding 区别有点大:Vibe reading 还是要完全理解论文内容的,但是 Vibe coding 甚至可以不用看代码
PDF 解析的问题
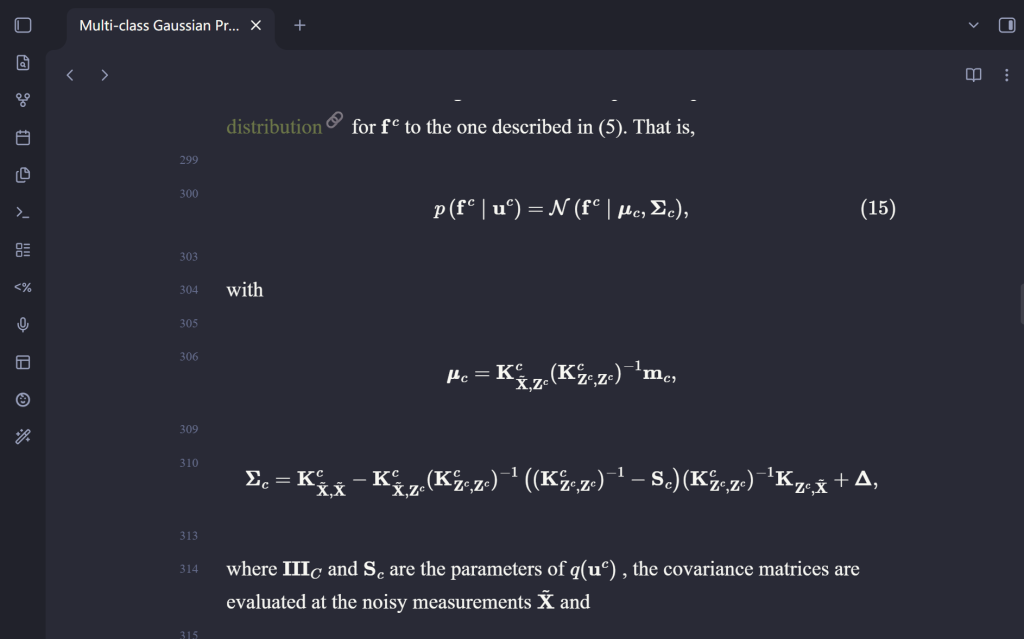
网页端 PDF 解析其实是一个问题,如果有类似经验的读者,其实应该能理解网页端 AI 目前的一个痛点,就是对于部分公式,区分不同字体简直是一个非常痛苦的事情,例如:
这几个在一般的PDF阅读器(例如 Zotero或者SumatraPDF)上直接复制都是 A ,但是在论文当中其意义天差地别,基于这个问题,目前我做的主要内容还是用一个相对更专业的OCR服务,目前用的是 MinerU ,由于没有打广告的意图读者可以自行查阅,目前来看解析效果还行。
目前最稳妥的方式是网页端解析了放回本地,当然还有个更时髦的方式——配制 Skills 😎,由于 MinerU 官方有 Openclaw 的 Skill,我是自己做了 Opencode 的 Skills。
对仓库的理解
Obsidian 仓库到底在这里可以起到什么作用?其实相比于网页端,我觉得它能提供的信息非常多:
- 你的语言习惯:你的语言是比较跳脱的?还是比较严肃不允许错误的,仓库里面的语言在这里会很有用,起码不会乱插一些 emoji 符号😇;
- 你的惯用符号:我的符号是小写普通字母就是实数,大写表示常数,粗体小写是向量,粗体大写是矩阵,这类习惯 AI 也能捕捉到,在 Prompt 里面写好“根据我笔记的符号使用习惯”即可;
- 承接 AI 语言:如果允许 AI 写 Markdown 文件和你交流,那么你可以看到更丰富的表达,包括更合理的公式、引用图表、编号等;
- 知识范围指引:仓库的所有知识如果能代表你的知识范围的话,对 AI 强调后可以解释地相对更加充分一些。
一个简单的例子就是苏格拉底式问答:让 AI 创建文件,你问它答在文件里面,这实际上就是扩展了网页端的交流方式,而且有受限的参考文献,它也能帮你链接,这点让我很惊喜🥰,GPT5.4 在了解我的笔记有什么了之后,会主动在新的笔记里面双链。
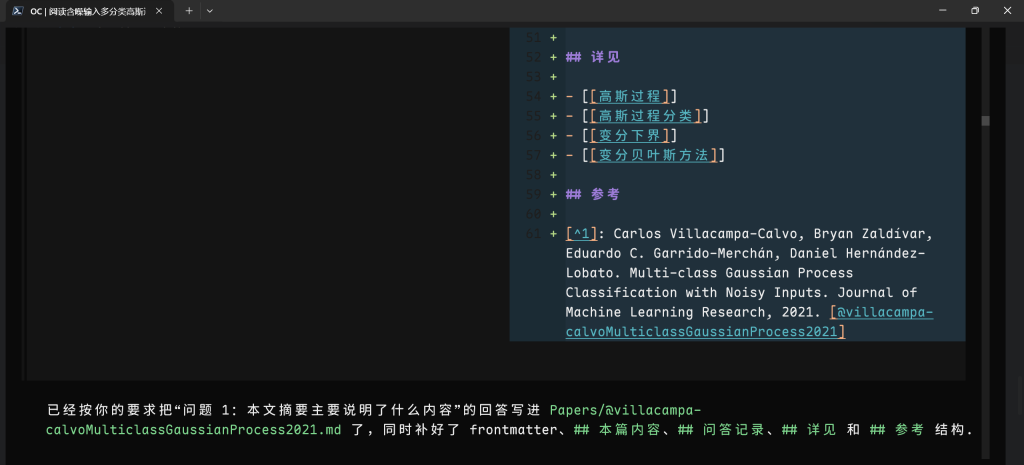
它捕捉到了我的固有格式,然后选择双链了我已有的笔记,当然,相应的参考文献也进行了引用和参考。
因此,我的主要时间就是直接用 Opencode 打开我的仓库,然后配制上述 MinerU 的 Skills 后,直接分析论文 PDF 文件,在这种情况下,的确有了不少改进,最近 Deepseek V4 Pro 出了之后,在这种长上下文场景下我们也可以使用它来解读文献,应该比 GPT 5.4 要感受好一些,至少钱包感受好些。
到这里其实也可以算是 Vibe Reading 了,个人觉得这将会是一段时间内解决开头提到的所有问题比较合理的方案。